
5 Steps to Build an AI-Powered Financial Statement Knowledge Graph
5 Steps to Build an AI-Powered Financial Statement Knowledge Graph
Recently we launched FootNoteDB Private, an AI-powered private internal database that we construct for each of our clients containing hundreds or thousands of their financial statements, making it easier to search and retrieve valuable information from their proprietary dataset. Our product and engineering team is rapidly iterating on our database infrastructure, applying advanced AI techniques to surface high-quality results.
We use a methodology called RAG (Retrieval Augmented Generation) to retrieve contextually relevant information from financial statements to run through an LLM (GPT-4o) and generate results from natural language queries. In our RAG methodology, we use an embedding model and vector database to help with the semantic understanding of the underlying documents.
While our embedding-based RAG methodology is very good at finding the exact thing a user asks for in a single document, it is not so great at finding related information across documents or related information in separate sections of a larger document.
The Solution: Hybrid Database Approach
We are considering a solution to add a knowledge graph to RAG by upgrading our RAG methodology to a hybrid database approach, including vector and graph databases. We can examine the whole picture by creating a knowledge graph derived from the financial statements. This graph-based approach to RAG maps how key concepts and data points in the financial statements are connected so related information can be found across documents and in separate sections of larger documents.
The following is our five-step framework to build an AI-powered knowledge base for analyzing financial data across large quantities of financial statements.
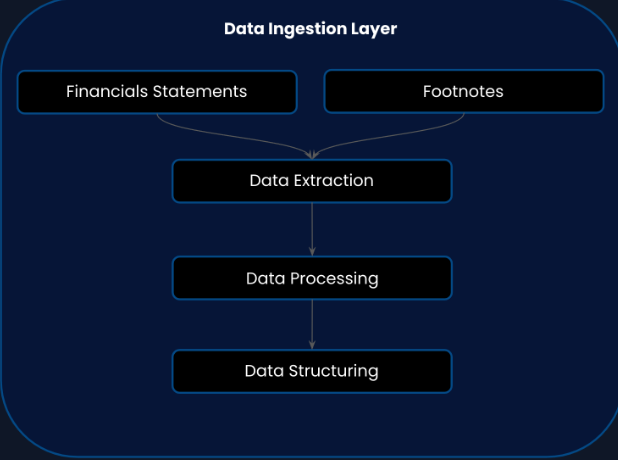
Step 1: Data Extraction and Data Structuring
We have built a data pipeline that utilizes a sequence of AI models to extract data from PDFs, transform unstructured content into a structured format, and tag the data. These models identify and separate objects such as:
- Characters, words, paragraphs, headers in text
- Cells, tables, and images
- Precise coordinates for each element
Beyond organizing the data, they retain precise coordinates for each element, ensuring that every piece of information can be traced back to its original location on the page.
Data Extraction Pipeline
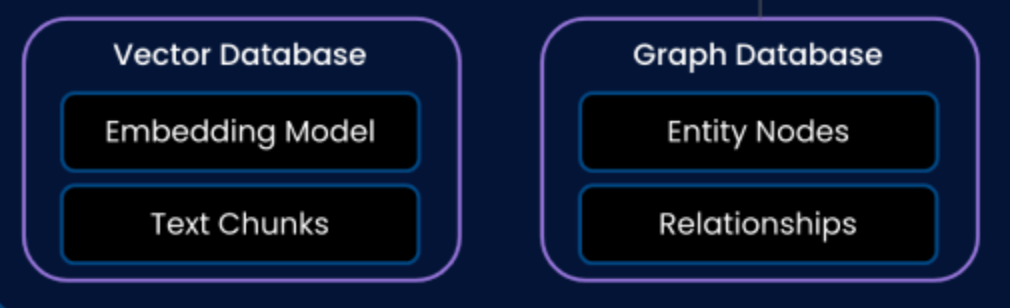
Step 2: Knowledge Base Architecture - A Hybrid Database Approach
We will use two types of databases in our knowledge base layer:
- Vector Database: Store and query embedded chunks of financial data
- Graph Database: Represent the nodes and relationships between financial concepts
This allows us to link concepts across documents, understand relationships inside financial statements, find commonalities between financial statements, and understand financial hierarchies.
Hybrid Database Architecture
Step 3: Ontology Development Strategy
To capture the richness and complexity of the financial statement data, we need to build an ontology as our foundation. By building an ontology, we can go beyond just storing data and use the power of LLMs for reasoning and inference.
For instance, if our ontology defines the relationship that "current assets minus current liabilities equals working capital," then we can infer new knowledge by automatically calculating working capital when we add data about assets and liabilities.
Using XBRL as Our Schema Foundation
We are considering using XBRL (eXtensible Business Reporting Language) as our schema for building our ontology. The tags in XBRL can be mapped to the concepts in our ontology, and our ontology can enrich the XBRL data by adding a layer of semantic meaning and relationships.
Then, we can add custom extensions like:
- Footnote-specific concepts not already tagged in XBRL
- Temporal attributes (dates, timestamps, durations, etc.)
- Contextual attributes (location, source, author, conditions, etc.)
LLM-Assisted Ontology Construction
The question then becomes: how do we map the XBRL concepts to the ontology? We can perform an LLM-assisted ontology construction and refinement using an XBRL schema modification process:
- Initial Construction: Use an LLM to analyze existing XBRL schema and build the first iteration of the ontology
- Human-in-the-Loop Refinement: Work closely with the LLM to refine various ontology sections
- Manual Enhancement: Add temporal and contextual attributes manually
- Expert Review: Our subject matter experts (CPAs) find gaps in footnote coverage and propose extensions for missing concepts
- Testing & Validation: Test and validate our ontology against real financial statement samples

Ontology Development Process
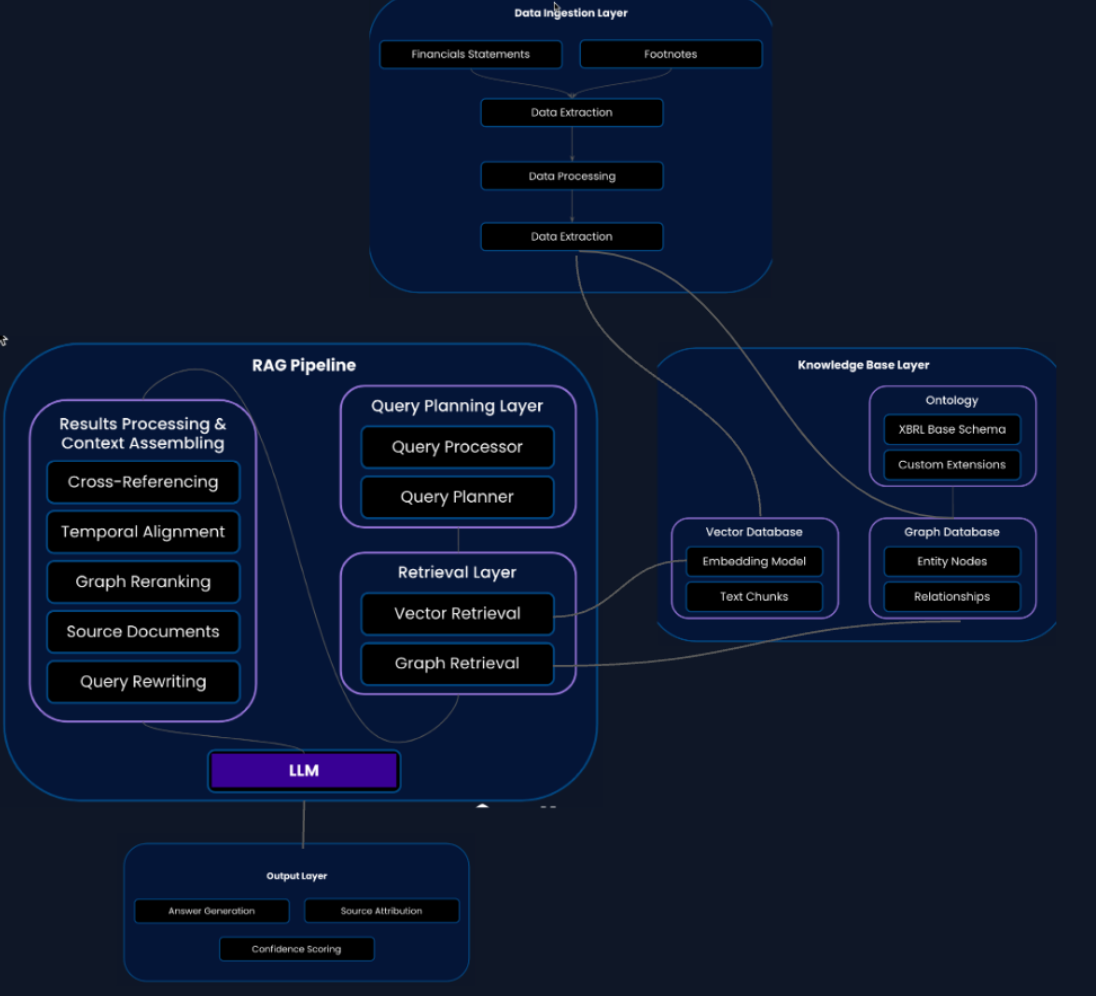
Step 4: RAG Implementation Architecture
We will build a multi-stage retrieval pipeline consisting of three main layers:
Query Planning Layer
Functions as the "brains" of the RAG pipeline, ensuring that the right information is retrieved to generate the best possible answer. This layer will:
- Understand the knowledge base architecture, including available databases and their underlying models (e.g., ADA-003 as embedding model and Neo4j as graph model)
- Query Processing: Uses LLM to analyze the query to understand its intent and key concepts, involving techniques like indexing, query rewriting, and query optimization
- Query Planning: Uses LLM to decide the most efficient way to find relevant information, selecting appropriate knowledge sources and search algorithms
Retrieval Execution Layer
The system that actually fetches the relevant information from our knowledge source. It will:
- Take the plan created by the query planner and execute it
- Retrieve the most relevant chunks of information from vector database, graph database, or hybrid retrieval for complex queries
- Rank and filter results based on relevance (e.g., BM25 keyword extraction)
- Format information suitably to feed into the language model
Results Processing Layer
Transforms the raw retrieved information into refined, well-structured, and informative context. Key techniques include:
- Cross-referencing Resolution: Automatically identify and link related pieces of information (e.g., balance sheet items with corresponding footnotes)
- Time-based Query Understanding: Analyze trends and changes over time, ensuring correct financial reporting periods
- Knowledge Graph-based Reranking: Identify semantically related chunks that might not have exact keyword matches (e.g., linking "debt" queries with lease liabilities)
- Source Document Listing: Link retrieved chunks back to original source documents for verification
- Query Rewriting: Clarify ambiguous or incomplete queries and expand scope to broader concepts

RAG Implementation Architecture
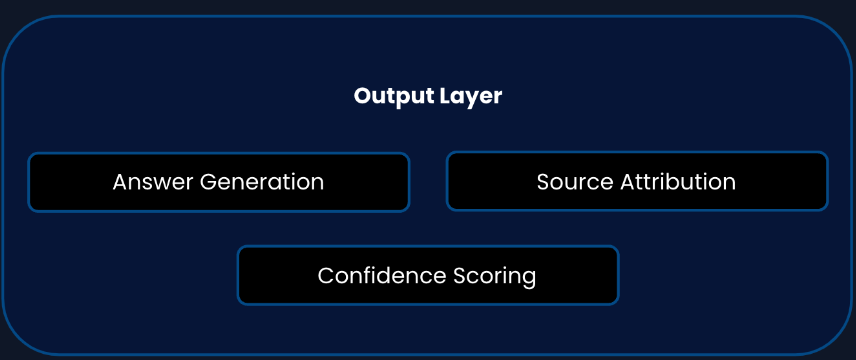
Step 5: Output Layer and Evaluation Framework
Our final step builds a framework for producing reliable, traceable results with comprehensive evaluation:
Output Components
- Answer Generation: LLM-generated responses based on retrieved context
- Source Attribution: Clear links back to original documents and data sources
- Confidence Scoring: Reliability metrics for each generated answer
Evaluation Framework
- Accuracy Metrics: Measure correctness of generated answers
- Retrieval Quality: Assess relevance and completeness of retrieved information
- User Experience: Track usability and satisfaction metrics
- Technical Validation: Performance benchmarking and system reliability testing
Output and Evaluation Framework
Applications and Future Potential
Our five-step framework for building an AI-powered knowledge base for financial statements is a significant undertaking with broad applicability. We are building it as part of our software to enable auditors to generate footnote disclosures for their financial statement preparation for middle-market clients.
However, this knowledge base likely has many applications across:
- Investment Analysis: Enhanced due diligence and financial modeling
- Finance Operations: Automated reporting and compliance monitoring
- Accounting Practice: Streamlined audit procedures and risk assessment
There are many other teams that could utilize this solution and may be building similar solutions. We welcome your feedback if you are working on a similar problem or have thoughts on this design.
Knowledge Graph Visualization
Get Started with FootNoteDB Private
If you run an accounting firm and would like to turn your financial statement repository into an AI-powered private database to automate the generation of footnotes, please reach out to us.
Special thanks to Subham Kundu for co-writing this blog post with me!